Patchwork Libraries
The hardest thing about studying massive quantities of digital texts is knowing just what texts you have. This is knowlege that we haven’t been particularly good at collecting, or at valuing.

The post I wrote two years ago about the Google Ngram chart for 02138 (the zip code for Cambridge, MA) remains a touchstone for me because it shows the ways that materiality, copyright, and institutional decisions can produce data artifacts that are at once inscrutable and completely understandable. (Here’s the chart–go read the original post for the explanation.)
Since then, I’ve talked a lot about the need to understand both the classification schemes for individual libraries, and the need to understand the complicated historical provenance of the digital sources we use.
What I haven’t done is give a real account of the sources of the books in Bookworm. That’s pretty hypocritical. I apologize. I decided some time ago to use the Open Library to provide all the metadata for Bookworm. It has very good, high-quality library metadata; but it doesn’t indicate where the metadata, or the volume itself, came from. (The meta-metadata, if you will, is not great.) That’s an ontological issue. Open Library describes “editions,” so there’s no space for a field that tells you where an individual pdf or text volume came from.
I recently loaded in this library data, though. The Internet Archive web site, which stores the actual books, does say where a particular volume comes from. So with a little behind the scenes magic, it’s pretty easy to get that into the database in some form.
I’ve been learning some D3 mock up a possible multi-dimensional interfaces to the Bookworm data through the API. (If you come to the Bookworm booth at the DPLA meeting next month, you can play with this as well as some new projects others in the lab have been building on the platform).
Using that, it’s possible to quickly mock up a chart of the… (drumroll)…
Library origins of the books in Bookworm. (Most common libraries only)
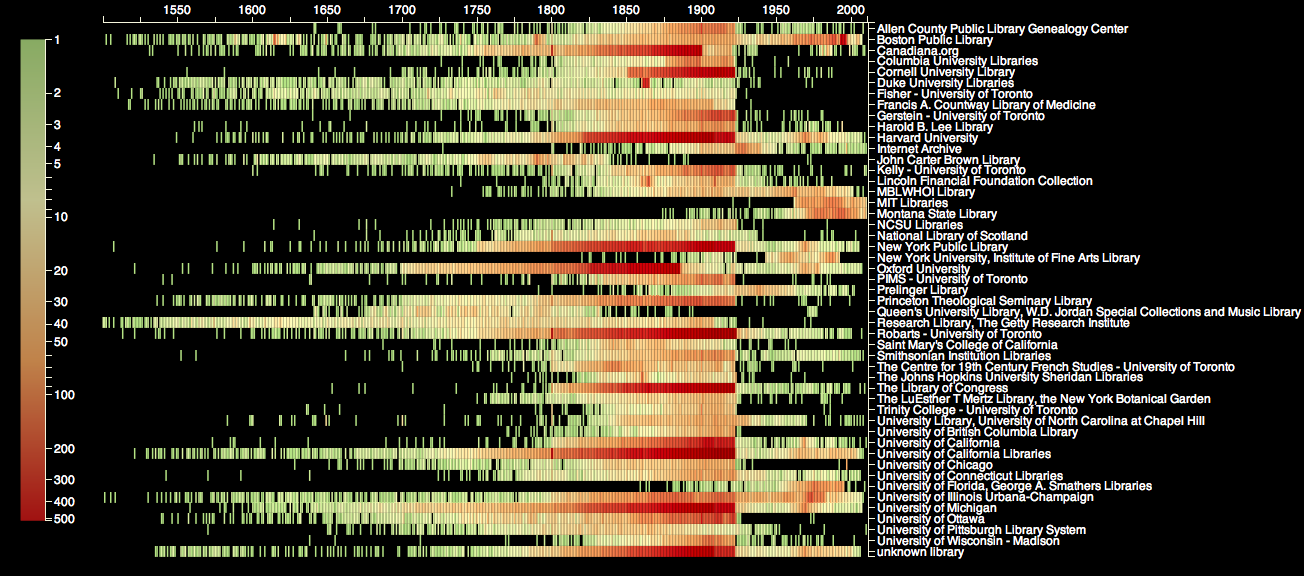
Click to enlarge
The colors are on a log scale here, and each little line represents a single combination of a library and year. So a red horizontal band is an area where a library has contributed hundreds of books to the Internet Archive (and therefore Bookworm) each year, a yellow to orange band means dozens of books a year, and the areas of scattered green show libraries that only contribute a volume or two every few years. I only show the most common libraries.
What can we see here? The number one contributor is the University of California Libraries. (No surprise). The Robarts library at the University of Toronto is number two–that’s only surprising to me because there have been so few books published in Canada when I’ve segmented by country. Most of the other large libraries are the ones you would expect_—_both some of the big university/Google partner libraries (Harvard, Oxford, Michigan, NYPL) and a few free agents who scanned on their own or in cooperation with the Internet Archive (Library of Congress, Boston Public (I think)).
The temporal patterns are more interesting. The 1922 cutoff line is the dominant visual feature of the chart–the extremely different composition of the lending libraries after that date (MIT and Montana State suddenly become important players, while sources like Cal and the LOC vanish). This is why comparisons across 1922 are never safe, even when the numbers seem big enough. But the complicated nature of the copyright line and scanning policies is also clear: for Canadiana.org, it’s 1900, and for Oxford, it seems to be in the 1880s. There are clearly some metadata problems, as well (I think a lot of those post-1922 Harvard books are misattributed).
There are also a lot of strange little clusters of intense collection. Duke and the Lincoln Financial collection have massive spikes from about 1861-1865; the Boston Public Library seems to have an abnormal number of books right around 1620 and 1776. Those are specifically historical collections that will affect the sort of conclusions one can draw from aggregate data, much like the questions I was asking about a Google presentation that purported to show that more history was published in revolutionary times). Although oddly enough, the first few BPL volumes from 1620 I checked were in French or Latin–it’s not quite the model of founding charters that I expected.
The digital libraries we’re building are immense patchworks. That means they have seams. It’s possible to tell stories that rest lightly across the many elements. But push too hard in the wrong direction, and conclusions can unravel. I don’t think that any conclusions I’ve made in the past are unsettled by knowing where the books came from–although that Oxford dropoff has me wondering what might happen to transatlantic comparisons. But I’m glad to be able to see it, and so wanted to share. This is something we need to do.
And this isn’t an issue particular to just Bookworm, although it does have a slightly more tangled line of transmission than some other libraries. Here, for example, are the top 16 libraries in the Hathi trust catalog from 1780 to 1820, scraped from their web catalog. 1800 is not a year that dramatically changes the publication history of books; but it is a year that librarians will use for their own arbitrary purposes. For instance, a book published in 1799 is considerably more likely to have been “rare” and therefore off limits to the Google scanners in the period of book scanning, I’d bet anything, just because human beings use rules of thumb like that; or in the period that university libraries were being built, acquisition policies may have been quite different for pre-1800 vs post-1800 texts in various genres. (“Don’t buy any science books written before 1800” would be a sensible policy to adopt in 1870, for example. Almost all the libraries here would not have bought the bulk of their 1799 collections in the year 1799.)
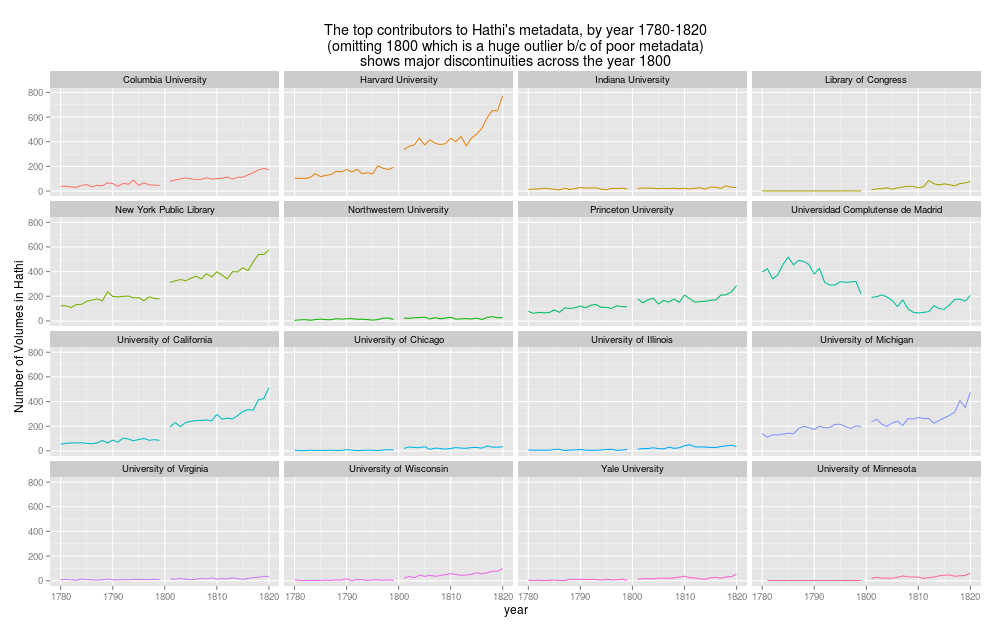
Click to enlarge
I pulled out the year 1800 (1800 and 1900 are both massive spikes where all sorts of unknown books can be filed). That also serves to highlight the gaps from 1799 to 1801; they’re sometimes quite significant. What you see here are the same sort of seams and discontinuities as in Bookworm, albeit on a smaller scale. The number of volumes from NYPL, Cal, and Harvard double overnight; other libraries, like Michigan and Madrid, seem not to show any pattern. If Michigan and California collect different sorts of books, this can cause major headaches for comparisons across the line.
Comments:
Anonymous - Apr 4, 2014
This comment has been removed by a blog administrator.
Anonymous - Jul 2, 2014
This comment has been removed by a blog administrator.