How Bad is Internet Archive OCR?
We all know that the OCR on our digital resources is pretty bad. I’ve often wondered if part of the reason Google doesn’t share its OCR is simply it would show so much ugliness. (A common misreading, ‘ tlie ’ for ‘ the ’, gets about 4.6m results in Google books). So how bad is the the internet archive OCR, which I’m using? I’ve started rebuilding my database, and I put in a few checks to get a better idea. Allen already asked some questions in the comments about this, so I thought I’d dump it on to the internet, since there doesn’t seem to be that much out there.
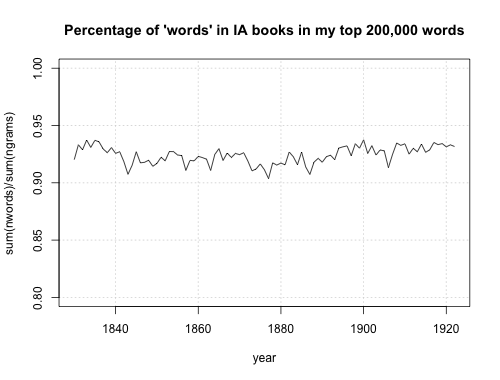
First: here’s a chart of the percentage of “words” that lie outside my list of the top 200,000 or so words. (See an earlier post for the method). The recognized words hover at about 91-93 percent for the period. (That it’s lowest in the middle is pretty good evidence the gap isn’t a product of words entering or leaving the language).
Now, that has flaws in both directions. Here are some considerations that would tend to push the OCR error rate on a word basis lower than 8%:
There are many real words and proper nouns that are under my 200,000 cutoff (although I suspect the actual count is not that money, and could probably prove this using Zipf’s law.)
Some books may be in entirely or partly foreign languages, and thus full of non-words.
A lot of the error words may be fragments where a word was split up into two chunks, but only one word was missed.
My Perl preprocessing script could be making punctuation related mistakes that create false words that aren’t OCR’s fault. (For instance, I run together hyphenated words).
The second is the big one there, I think.
Things might make the error rate higher than 8%:
Some of the error words may be concatenations of two words. (This isn’t as likely, I don’t think, as the reverse).
Misreadings might confuse two real words–‘ them ’ for ‘ then ’, for example.
I’m already counting a lot of typos as words in my top 200,000. Just eyeballing some randomly selected lists, I’d guess as many as half of my ‘ words ’ are actually typos.
I’m sure there are others in both directions.
I would think the biggest outstanding reason is all the misreadings that are so common my perl script takes them to be words. Skim this list, if you like, of a random selection of the words I’m using:
> words[sample(1:nrow(words),30),]
word count stem
169825 thiiigs 138 thiiig <- (misreading of ‘ things ’)
4543 alcaydes 326 alcayd
135174 poww 379 poww
12068 auricularis 167 auriculari
113516 moyed 730 moi
63398 florin 1756 florin
150309 sawney 381 sawnei
120030 nye 2113 nye
128509 peajacket 458 peajacket
152493 seleucidae 237 seleucida
114066 mulder 575 mulder
127922 pastrycook 514 pastrycook
113269 moud 174 moud
134 aaoh 238 aaoh<- (I can’t tell from texts what this is)
84436 imitable 324 imit
90520 ixi 3748 ixi
148794 sacris 826 sacri
53102 emere 272 emer
49575 dulls 690 dull
136241 prevaricated 207 prevar
27222 caviar 419 caviar
152210 seei 484 seei <- (misreading of ‘ seen ’ or ‘ seek ’?)
40027 cvv 169 cvv
66494 frustrates 319 frustrat
98422 leggere 283 legger
34009 complaisantly 138 complaisantli
190102 wliieh 3762 wliieh <- (misreading of ‘ which ’)
8998 apriori 382 apriori
142431 recruitment 358 recruit
163656 subsultus 255 subsultu
Some of those are foreign words, but a lot are obviously typos. It would be _great_ for my database if I could just drop out all the typos, so I’d love advice on how to do that–I’ve thought about just running some clustering routines on frequent typos to see what words appear disproportionately often in books with bad OCR, but that might be risky.
So what percentage of words are typos? That’s really hard to say, but let me give some examples. Perl regexes inside R let us look for some of the common misreadings I’ve noticed: we can look for every word that has some characters characters commonly misread as each part of ‘ the ’; ‘ f ’ for ‘ t ’, ‘ li ’ for ‘ h ’, and so forth.
(t|l|i|f)(h|b|li|ii|n|ji|ti|t|l|m|fi)(e|c):
> words[grep(“^[ltif](b|li|ii|n|ji|ti|t|l|m|fi|h)[ce]$”,words[,1],perl=T),c(1,2)]->local; local[order(local[2],decreasing=T),]
word count
169158 the 197439894
172443 tlie 738290
167183 tbe 525324
82755 ihe 218396
171326 tiie 162834
173001 tne 67567
81669 ibe 65536
172422 tlic 58502
101354 llie 51008
82737 ihc 33725
…
Putting every word that looks like “the” together, I get about 2.2 million words. Not all of those as actually misreadings of ‘ the ’ (some are probably weird words, some are misreadings of “this”, “line”, or whatever), but that’s probably a good ballpark guess. There are about 196 million occurrences of “the” in the flesh in the database. So that’s an error rate of about 1% on the (somewhat) obvious misreadings of a short word. I think ‘ h ’ is one of the harder characters to read, based on the errors I’ve looked at, so that would imply IA OCR is well above 99% accurate on a character basis. (One study on the IA site found 99.6-99.9% accuracy on more modern texts, so that doesn’t seem unreasonable for the whole corpus).
Another way we might find errors is by looking for lone letters. “A” and “I” excepted, these make up about 1% of the words in my sample; two letters words less common than ‘ ye ’, which seems to be about the cutoff between real words and errors, make up about 0.8%. (And both those counts include a number of legitimate initials, roman numerals, etc.) Since each individual detached letter or two letter chunk probably indicates only a fraction of a missed word, this isn’t terrible.
So what’s the conclusion? I suspect that over 85% of words overall are correct in the IA scans, and possibly as much as 90%. The error rates are high enough, though, that using this for sentence processing is problematic–word counts should work all right, though we should be aware that the incidence of longer words is probably slightly underrepresented. Still, I don’t see much that indicates using words is going to be dramatically flawed except in a few cases we should watch out for, such as when a word might be a misreading for one a hundred times more common.
And finally, these are dragged down by a few bad apples. Here’s a usage example of ‘ ifie ’, which I suspected was a typo for ‘ the ’, from an 1847 edition of Scott’sWaverley Novels:
“i tve flyron a lciimifiil dagger mounted with coldwbicu lifui bccn ttic ptopirty of ifie rcdouhtix klfi ucy lbt i wiie to play tlic part if dionied in the jliajj cur byron sent mt so mi”
The median percentage of words in my sample is 94.2%, which is a little higher than the mean of 93.1% see at the top. The best book is 98.2% accurate.
Comments:
Instead of perl hacking on your own, why don’t…
Anthony - Dec 3, 2010
Instead of perl hacking on your own, why don’t you try to apply an already existing algorithm for OCR cleanup and see what happens? Something like this: http://www.springerlink.com/content/l2724747mt78039l/
agreed with Anthony (above), it’s good to see …
Anonymous - Dec 3, 2010
agreed with Anthony (above), it’s good to see you working out these problems. again, though, i think you’re too centered on *your* database and monkeying around with it - this is good information to have for those of us also interested in building a database, but these methodological points seem to be the focus, whereas one could imagine some of your blog content moving over into actual sustained attention to a single historical problem/issue. you can do it! i think now’s the time, and these methodological posts can run right alongside that sort of work. what do you have in mind?
Great work Ben. To be clear, I think there’s a…
Allen Riddell - Dec 4, 2010
Great work Ben. To be clear, I think there’s an issue with some of the IA’s OCRing of Google books. It’s not a general comment about IA’s OCR.
The issue I’m really thinking about is what might happen if you were working with a small(er) sample (say, 100-1000 books) and you mixed texts with significantly different OCR quality. I can imagine some sort of difference in vocabulary being an artifact of OCR. And the effect would be magnified if one was doing principle component analysis.
In other words, let’s say you were interested in the frequency of the word “universal” and a certain group of texts, having poor OCR, had one in every 20 words misspelled.
Another thought: what if spelling errors are more likely to crop up in longer words? What if the error rate was 20% for words longer than 8 characters. I feel like these issues are important to address if work in text analysis in the “digital humanities” wants to be taken seriously by folks in other disciplines. Is this being overly cautious?
I now remember how/why I got concerned about this….
Allen Riddell - Dec 4, 2010
I now remember how/why I got concerned about this. I was working with a smaller dataset (100 19th century novels) and I decided to use a *very* rough metric of OCR quality: percentage of words misspelled (by a modern word spell checker, aspell).
I found that the difference was considerable.
Here’s a google-IA-rescan with 7% misspelled words:
http://www.archive.org/details/contariniflemin04disrgoog
The IA scan of the same novel has 3% misspelled words. ID: contarinifleming04disr
And a google epub version, once I stripped the raw text, has 2% misspelled words. Google ID: mhK7xT4Bc3wC
It’s important to note that Google epubs are end-of-line dehyphenated so I’m sure that helps the metric.
I like this post very much!
Clipping Path - May 5, 2014
I like this post very much!
There are some men who, years after being in a rel…
Color corection Service - Sep 3, 2014
There are some men who, years after being in a relationship, continue to treat their women like if it was just yesterday that they got together.