I’ve been seeing how deeply we could integrate topic models into the underlying Bookworm architecture a bit lately.
My own chief interest in this, because I tend to be a little wary of topic models in general, is in the possibility for Bookworm to act as a diagnostic tool internally for topic models. I don’t think simply plotting description absent any analysis of the underlying token composition of topics is all that responsible; Bookworm offers a platform for actually accessing those counts and testing them against metadata.
But topics also have a lot to offer token-based searching. Watching links into the Bookworm browser, I recently stumbled on this exchange:
How can I solve this biologist’s problem? (Or, at least, waste more of his time?)
The word-level topic assignments I have on hand are actually real useful for this. (I’m assuming, I should say, that you know both the basics of topic modeling and of the movie bookworm.) I can ask the beta bookworm browser for the top topics associated with each of the words “fly” (top) and “ant” (bottom):
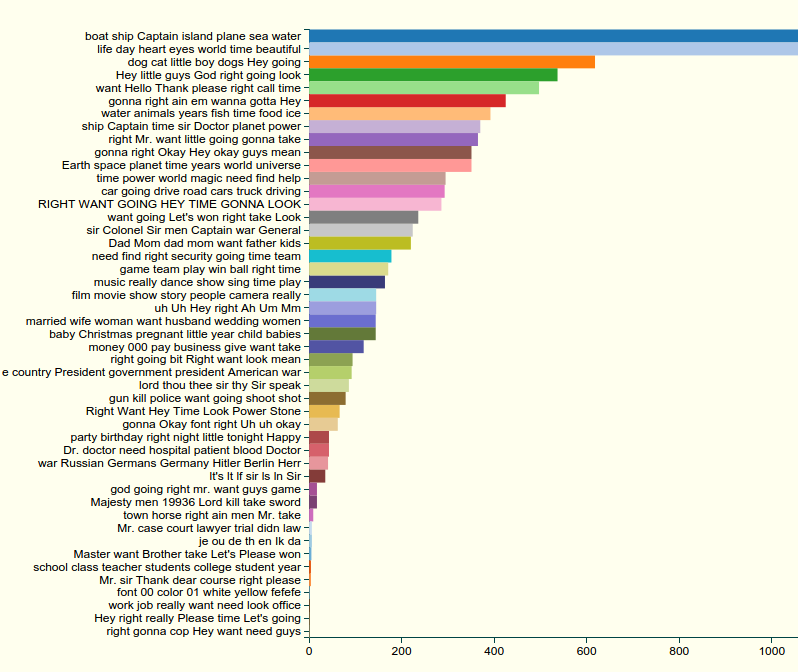
Fly usage by topic

Ant usage by topic
“Fly” is overwhelmingly associated with the topics “boat ship Captain island plane sea water” (airplane flying) and “life day heart eyes world time beautiful” (unclear, but might be superman flying). (It’s even more so than on this chart, since I’ve lopped off the right side: there are about 2200 uses of “fly” in the first topic).
But “ant” is most used in two clearly animal related topics: “water animals years fish time food ice” and “dog cat little boy dogs Hey going.” And both of those topics show up for “fly” as well.
So in theory, at least, we can *restrict searches by topic:* rather than put into a Bookworm *every* usage of the word “fly”, we can get only those that seem, statistically, to be used in an animal-heavy context.
With an imperfect, 64-topic model on a relatively small corpus like the Movie Bookworm, this is barely worth doing.
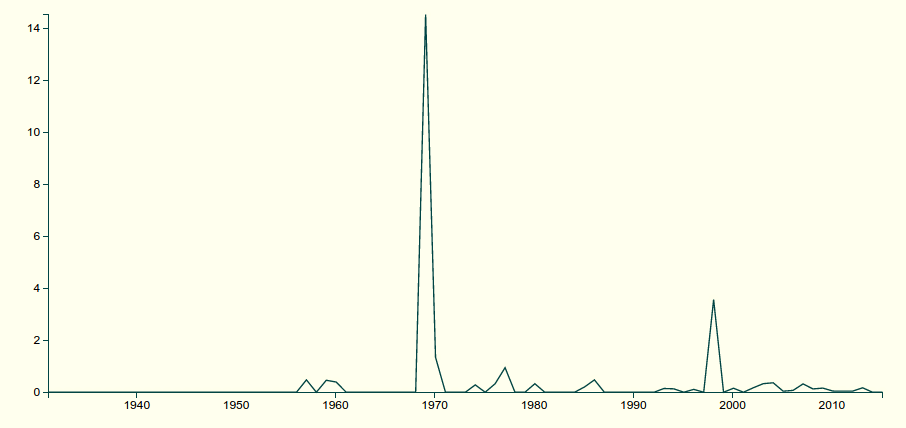
Ant in animal topics per million words in all topics
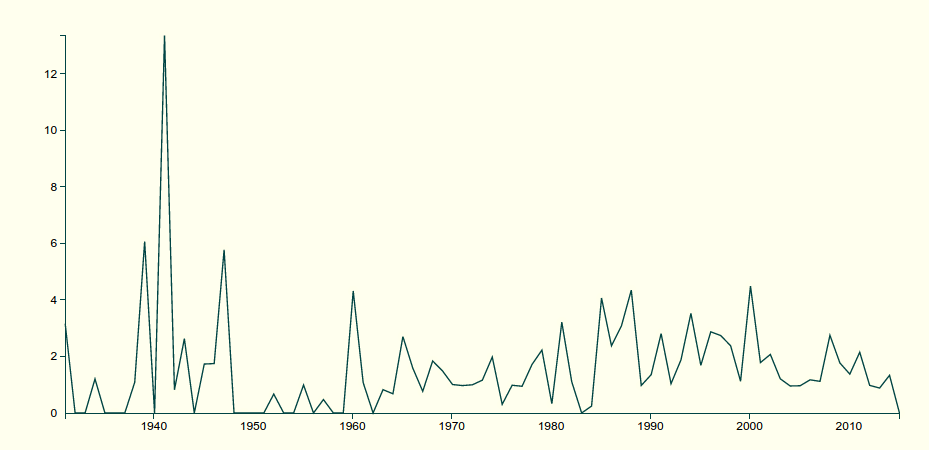
Fly in animal topics per million words in all topics
And given that “flying” is something that plenty of animals do, the “fly” topic here is probably not all Order Diptera.
But with collections the size of the Hathi trust, this could potentially be worth exploring, particularly with substantially larger models. “Evolution” is one of the basic searches in a few bookworms: but it’s hard to use, because “evolution” means something completely different in the context of 1830s mathematics as opposed to 1870s biology. A topic model that could conceivably make a stab at segregating out just biological “evolution,” though, would be immensely useful in tracing out Darwinian changes; one that could disentangle military shooting from the interjection “shoot!” might be good at studying slang.
Above all, this might be good at finding words that migrate meanings in early uses: most new phrases actually emerge out of some early construction, but this would let us try to recover meaning through context.
Hell, it might even have an application in Prochronisms work; given a large, pre-built topic model, any new scripts could be classified against it and their words assigned to topics, and tested for their appropriateness as a topic-word combination.
Technical note: the basics of this are pretty easy with the current system: the only issue with incorporating “topic” as a metadata field on the primary browser right now is that the larger corpus it compares against would also be limited by topic. This could be solved by using the asterisk syntax that no one uses: {“*topic”:[3],”*word”:[“fly”]} will ensure both are dropped, not just one, by just specifying the “compare_limits” field manually.