This is a post about several different things, but maybe it’s got something for everyone. It starts with 1) some thoughts on why we want comparisons between seasons of the Simpsons, hits on 2) some previews of some yet-more-interesting Bookworm browsers out there, then 3) digs into some meaty comparisons about what changes about the Simpsons over time, before finally 4) talking about the internal story structure of the Simpsons and what these tools can tell us about narrative formalism, and maybe why I’d care.
It’s prompted by a simple question. I’ve been getting a lot of media attention for my Simpsons browser. As a result of that, I need some additional sound bytes about what changes in the Simpsons. The Bookworm line charts, which remain all that most people have seen, are great for exploring individual words; but they don’t tell you _what words to look for. _This is a general problem with tools like Bookworm, Ngrams, and the like: they don’t tell you what’s interesting. (I’d argue, actually, that it’s not really a problem; we really want tools that will useful for addressing specific questions, not tools that generate new questions.)
The platform, though, can handle those sorts of queries (particularly on a small corpus like the Simpsons) with only a bit of tweaking, most of which I’ve already done. To find interesting shifts, you need:
1) To be able to search without specifying words, but to get results back faceted by words;
2) Some metric of “interestingness” to use.
Number 1 is architecturally easy, although mildly sort of expensive. Bookworm’s architecture has, for some time, prioritized an approach where “it’s all metadata”; that includes word counts. So just as you can group by the year of publication, you can group by the word used. Easy peasy; it takes more processing power than grouping by year, but it’s still doable.
Metrics of interestingness are a notoriously hard problem; but it’s not hard to find a _partial _solution, which is all we really need. The built-in searches for Bookworm focus on counts of words and counts of texts. The natural (and intended) use are the built-in limits like “percentage of texts” and “words per million,” but given those figures for two distinct corpora (the search set and the broader comparison sets) also make it possible to calculate all sorts of other things. Some are pretty straightforward (“average text length”); but others are actual computational tools in themselves, including TF-IDF and two different forms of Dunning’s Log-Likelihood. (And those are just the cheap metrics; you could even run a full topic model and ship the results back, if that wasn’t a crazy thing to do).
So I added in, for the time being at least, a Dunning calculator as an alternate return count type to the Bookworm API. (A fancy new pandas backend makes this a lot easier than the old way.) So I can set two corpora, and compare the results of each to each.
To plow through a bunch of different Dunning scores, some kind of visualization is useful.
Last time I looked at the Dunning formula on this blog, I found that Dunning scores are nice to look in wordclouds. I’m as snooty about word clouds as everyone else in the field. But for representing Dunning scores, I actually think that wordclouds are one of the most space-efficient representations possible. (This is following up on how Elijah Meeks uses wordclouds for topic model glancing, and how the old MONK project used to display Dunning scores).
There’s aren’t a lot of other options. In the past I’ve made charts for Dunning scores as bar charts: for example, the strongly female and the most strongly male words in negative reviews of history professors on online sites. (This is from a project I haven’t mentioned before online, I don’t think; super interesting stuff, to me at least). So “jerk,” “funny,” and “arrogant” are disproportionately present in bad reviews of men; “feminist,” “work,” and “sweet” are disproportionately present in bad reviews of women.
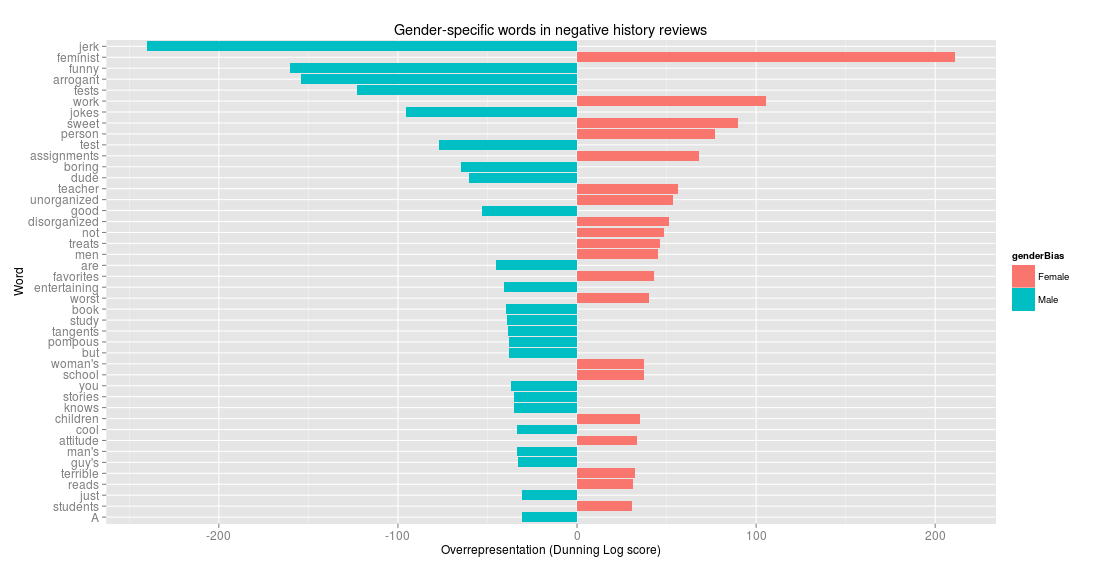
This is a nice and precise way to do it, but it’s a lot of real estate to take up for a few dozen words. The exact numbers for Dunning scores barely matter: there’s less harm in the oddities of wordclouds (for instance, longer words seeming more important just because of its length).
We can fit both aspects of this: the words and the directionality–by borrowing an idea that I think the old MONK website had; colorizing results by direction of bias. So here’s one that I put online recently: a comparison of language in “Deadwood” (black) and “The Wire” (red).

This is a nice comparison, I think; individual characters pop out (the Doc, Al, and Wu vs Jimmy and the Mayor); but it also captures the actual way language is used, particularly the curses HBO specializes in. (Deadwood has probably established an all-time high score on some fucking-cucksucker axis forever; but the Wire more than holds it own in the sphere of shit/motherfucker.) This is going to be a forthcoming study of profane multi-dimensional spaces, I guess.
Anyhoo. What can that tell us about the Simpsons?
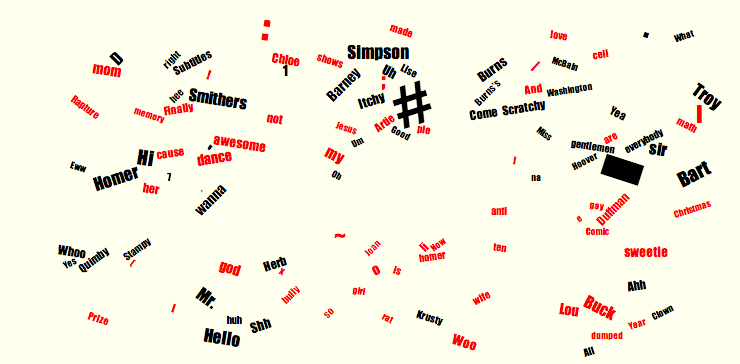
Here’s what the log-likelihood plot looks like. Black are words characteristic of seasons 2-9 (the good ones); red is seasons 12-19. There’s much, much less that’s statistically different about two different 80-hour Simpsons runs than two roughly 80-hour HBO shows: that’s to be expected. And most the differences we do find are funny things involving punctuation that have to do with how the Bookworm is put together.
But: there are a number of things that are definitely real. First is the fall away from several character names. Smithers, Burns, Itchy _and _Scratchy (Itchy always stays ahead), Barney, and Mayor Quimby all fall off after about season 9. Some more minor characters (McBain drop away as well.)
Few characters increase (Lou the cop; Duffman; Artie Ziff, though in only two episodes). Lenny peaks right around season 9; but Carl has had his best years ever recently.
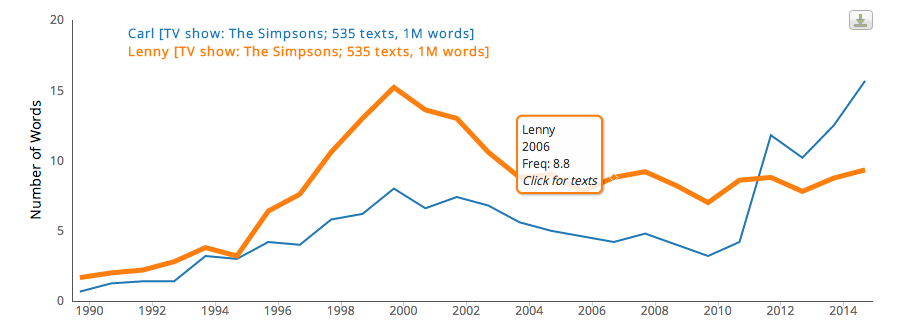
We do get more, though, of some abstract words. Even though one of the first appearances was a Christmas special, “Christmas” goes up. Things are more often “awesome,” and around season 12 kids and spouses suddenly start getting called “sweetie.” (Another project would be to match this up against the writer credits and see if we could tell whether this is one writer’s tic.)
“Gay” starts showing up frequently.
Others are just bizarre: The Simpsons used the word “dumped” only once in the 1990s, and a 19 times in the 2000s. This can’t mean anything (right?) but seems to be true.
What about story structure? I found myself, somehow, blathering on to one reporter about Joseph Campbell and the hero’s journey. (Full disclosure: I have never read Joseph Campbell, and everything I know about him I learned from Dan Harmon podcasts).
But those things are interesting. Here are the words most distinctively from the first act (black) and the third act (red). (Ie, minutes 17-21 vs 2-8).

As I said earlier, school shows up as a first-act word. (Although “screeching,” here, is clearly from descriptions of the opening credits, school remains even when you cut the time back quite a bit, so I don’t think it’s just credit appearances driving this). And there are a few more data integrity issues: elderman is not a Simpsons character, but a screenname for someone who edits Simpsons subtitles; www, Transcript, and Synchro are all unigrams about the editing process. I’ll fix these for the big movie bookworm, where possible.
That said, we can really learn something about the structural properties of fictional stories here.
Lenny is a first act character, Moe a third act one.
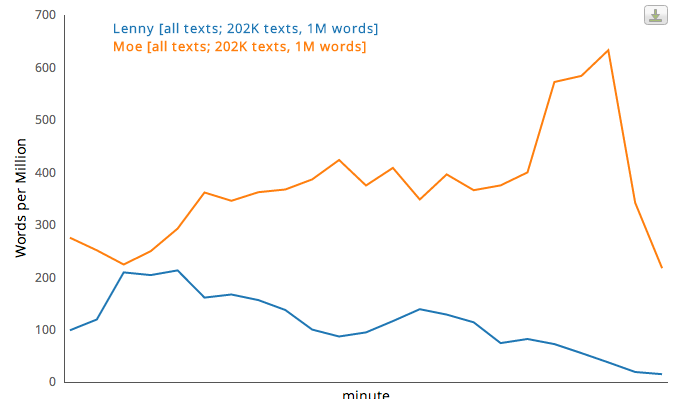
We begin with “school” and “birthday” “parties;”
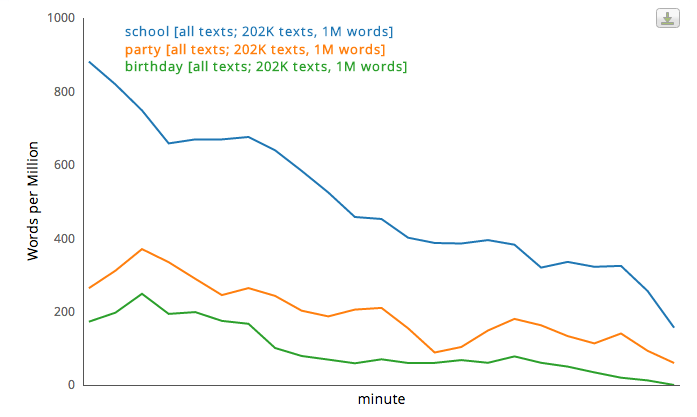
we end with discussions of who “lied” or told the “truth,” what we “learned” (isn’t that just too good?), and, of course with a group “hug.” (Or “Hug”: the bias is so strong that both upper- and lower-case versions managed to get in). And we end with “love.”
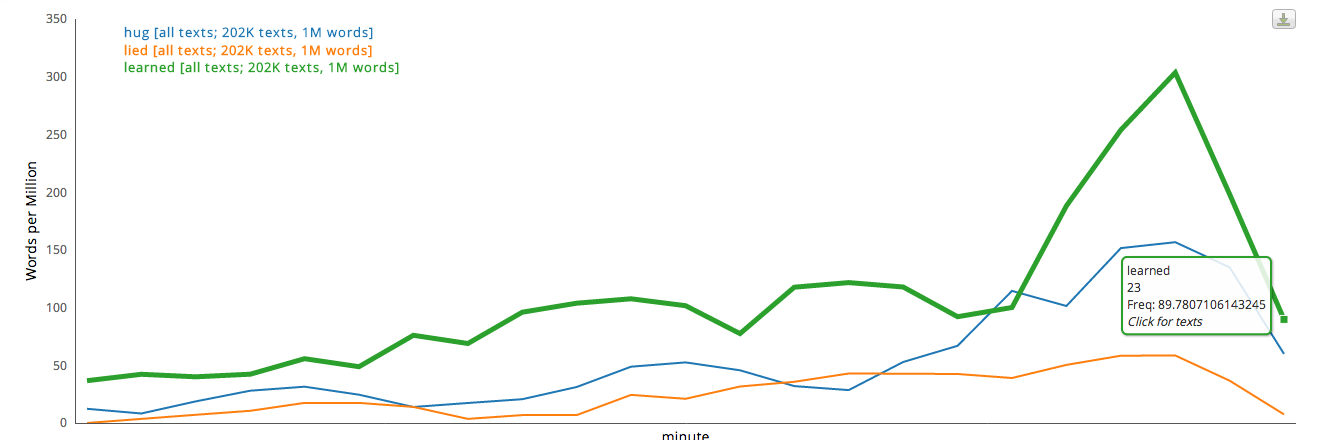
The hero returns from his journey, having changed.
Two last points.
First, there are no discernably “middle” words I can find: comparing the middle to the front and back returns only the word “you,” which indicates greater dialogue but little else.
Second: does it matter? Can we get anything more out of the Simpsons through this kind of reading than just sitting back to watch? Usually, I’d say that it’s up to the watcher: but assuming that you take television at all seriously, I actually think the answer may be “yes.” (Particularly given whose birthday it is today). TV shows are formulaic. This can be a weakness, but if we accept them as formulaically constructed, seeing how the creators are playing around with form can make us appreciate them better, better appreciate how they make us feel, and how they work.
Murder mysteries are like this: half the fun to all the ITV British murder mysteries is predicting who will be the victim of murder number 2 about a half hour in; all the fun of Law and Order is guessing which of the four-or-so templates you’re in Wrongful accusation? Unjust acquittal? It was the first guy all along? (And isn’t it fun when the cops come back in the second half hour?)
But the conscious play on structures themselves are often fantastic. The first clip-show episode of _Community _is basically that; essentially no plot, but instead a weird set of riffs on the conventions the show has set for itself that verges on a deconstruction of them. One could fantasize that we’re getting to the point where the standard TV formats are about as widespread, as formulaic, and as malleable as sonata form was for Haydn and Beethoven. What made those two great in particular was their use of the expectations built into the form. Sometimes you don’t want to know how the sausage is made; but sometimes, knowing just gets you better sausage.
And it’s just purely interesting. Matt Jockers has been looking recently at novels and their repeating forms; that’s super-exciting work. The (more formulaic?) mass media genres would provide a nice counterpoint to that.
The big, 80,000 movie/TV episode browser isn’t broken down by minute yet: I’m not sure if it will be for the first release. (It would instantly become an 8-million text version, which makes it slower). But I’ll definitely be putting something together that makes act-structure possible.