I thought it would be worth documenting the difficulty (or lack of) in building a Bookworm on a small corpus: I’ve been reading too much lately about the Simpsons thanks to the FX marathon, so figured I’d spend a couple hours making it possible to check for changing language in the longest running TV show of all time.
For some thoughts on how to build a bookworm, read “prep”: otherwise, skip to analysis. Or just head over the browser.
Prep
Step one is getting the texts. This is easy enough here, something I know how to do from all my Prochronisms posts: I can just use the subtitles, which are available a batch at a time. The only challenge is deciding what to do with audio-effects subtitles. I’m deciding to download the files that include them where necessary, but probably disable them by default. I also end up with only 540-something episodes, about ten short of the complete run: rather than try to figure that out at the start, I’m going to let the Bookworm data visualizations themselves be the clue to what I’m missing.
Next up is choosing what a “text” will be. The obvious choice would be for each episode to be a single text: but 550 episodes, while it’s a lot to watch, doesn’t give many angles for analysis. My second idea is that it might be interesting to look at a really granular level: ideally, we’d be able to compare the first, second, and third acts. That info isn’t in the subtitles, but we can split up by lines of speech: later on, we’ll be able to aggregate the queries to look in just the first hundred lines, or the first third, or whatever. The only downside is that it dramatically increases the number of texts: but that’s not really a huge problem.
That also makes it easy to decide what I’ll display in the search results: the individual line from the script containing the word.
Next step is to parse into bookworm format. Since these are in SRT format, it’s not as easy as it could be: I’m looking to create indexes that are episode-season-line. To get the season and episode names, I write out some regular expressions that match the various different filenames. This one of the uglier parts, and where I actually spend the most time. The final parsing code uses a whole bunch of regexes to handle the different formats people use: “S04E20”, “[1.3],” and so forth. One batch doesn’t have season numbers at all: I’ll have to fix that later.
def parseFilename(string):
form1 = r"[sS](\d\d?)[eE](\d\d?)"
form2 = r"(\d\d?)x(\d\d?)"
form3 = r"\[(\d\d?)\.(\d\d?)"
for regexp in [form1,form2,form3]:
matches = re.findall(regexp,string)
if len(matches) > 0:
return matches[0]
return ("",re.sub(".*Episode (\d\d).*",r"\1",string))
Next is actually parsing the text, and adding some new information to it about the position of each line. This is usually the hardest part, but SRT parsing is pretty easy as these things go. Plus, nailing down the format leads me to an insight–rather than use line number, I can take the embedded time information in the SRT files and index by the minute and second in the episode that a subtitle flashes on the screen. Each subtitle block will correspond to a file, and we’ll know the exact moment it appeared. Turns out there are about 200,000 of those in the series, which is a reasonable number of texts to include in a Bookworm. (Though if I were hypothetically to do this for a whole bunch of TV series (more than a couple hundred) at the same time, that might push the system’s limits.) Parsing out the SRT time information works well. We’re left with some straggling sound effects, which I’m just leaving in for the time being. Occasionally characters names appear at the front of texts: again, that’s something I’d correct if this were a weekend project rather than a weeknight one.
That means the final scheme will give us, for each subtitle block:
Season Number
Episode number in the season
Episode number in the series (will make some plots easier).
Minute in the episode
Second in the episode
The actual text of the block.
From that information, if we were true Simpsons scholars, we could easily add:
Act (roughly: call minutes 0-7 act 1, minutes 8-14 act 2, and minutes 15 to the end act 3)
Air date, episode director, and other information easily linkable from IMDB.
Whether it’s a finale or what.
Once the text is parsed, the file-creation is pretty easy, we’re ready to ingest. The input.txt file is just the text and an id number constructed from the moment the block appears on screen: the jsoncatalog.txt is just a dump of an object that’s useful for processing, anyway.
I’ve already written a specialized makefile for my Federalist papers bookworm to clone the Bookworm repo and put files in the right place, so that’s easily adapted.
And then we’ve got it! I didn’t designate any fields as “time,” so a first inspection will be easier using the D3 browser.
The first test is to find out about those pesky missing episodes. So I’ll plot a heatmap of the number of words for each episode (x axis) and season (y axis):
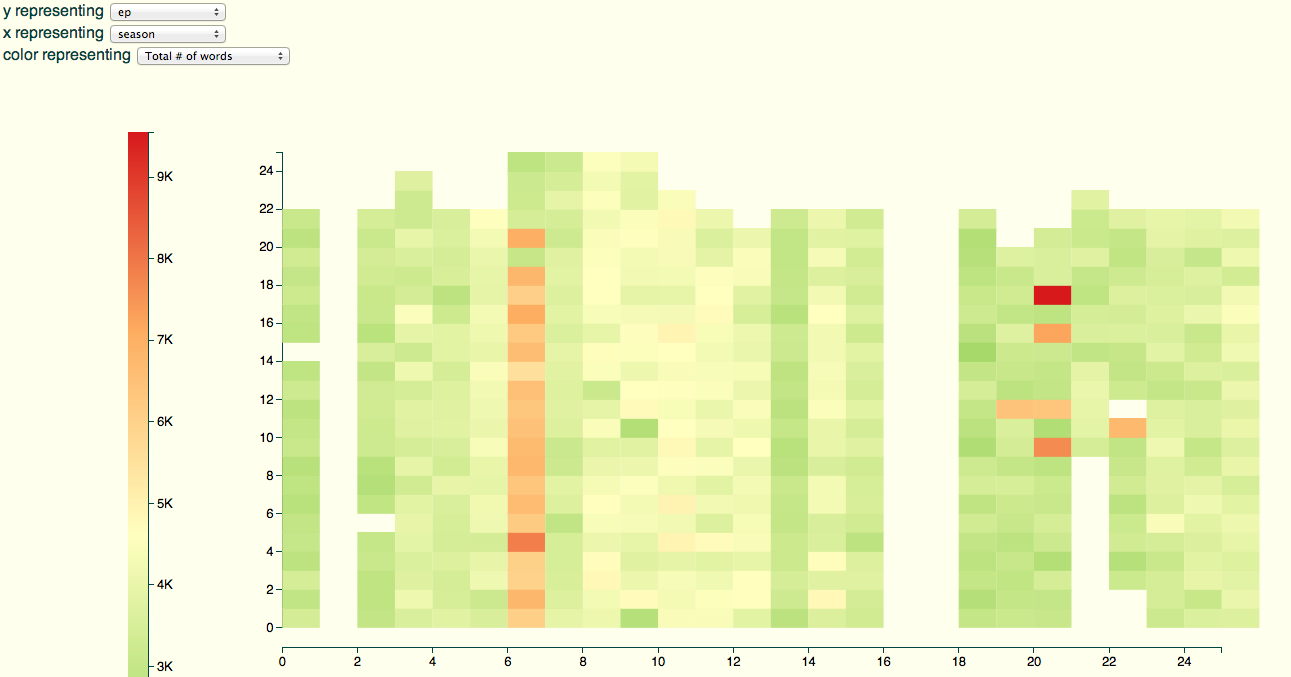
This shows that we’ve got about 25 episodes for season, but: we’ve got a season 0 and no season 1 (that one set of srts that didn’t give a season, no doubt); we’ve got no seasons 16 and 17; and, curiously, most season 6 episodes are twice as long as they should be. Probably season 16 was mislabeled season 6, and we’re actually missing season 17. We’re also missing the first 9 episodes of season 21, and the first two of season 22. Oh well. Something to catch on a next run.
Analysis
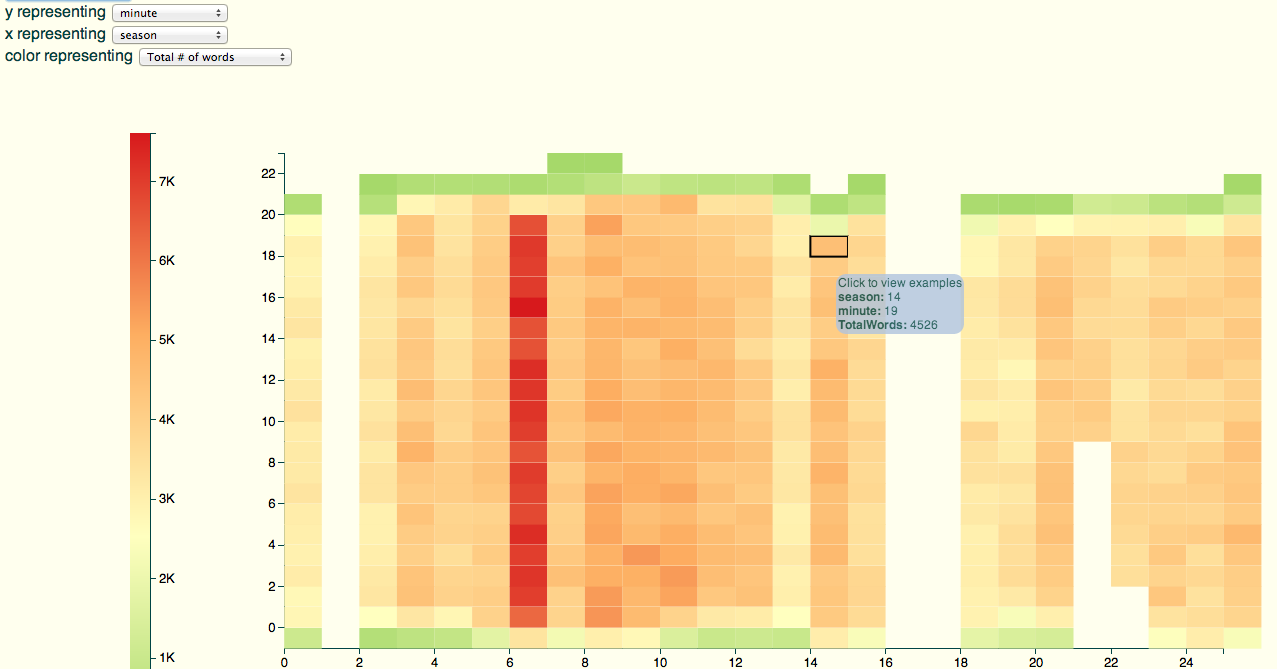
The beta lets us quickly check out some other things, like the number of words (color) by *minute* (y axis) and season (x): you can see commercial creep, as sometime around season 14 we lose most of minute 21.
OK: let’s check the actual words. Here are uses of each of the central four characters: season on the x axis, unigram on the y axis.
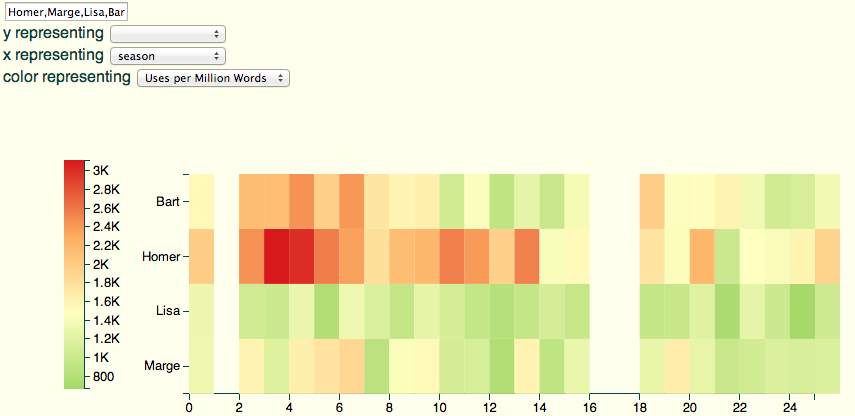
Nothing too suspicious here: the shift from Bart to Homer looks good, etc.
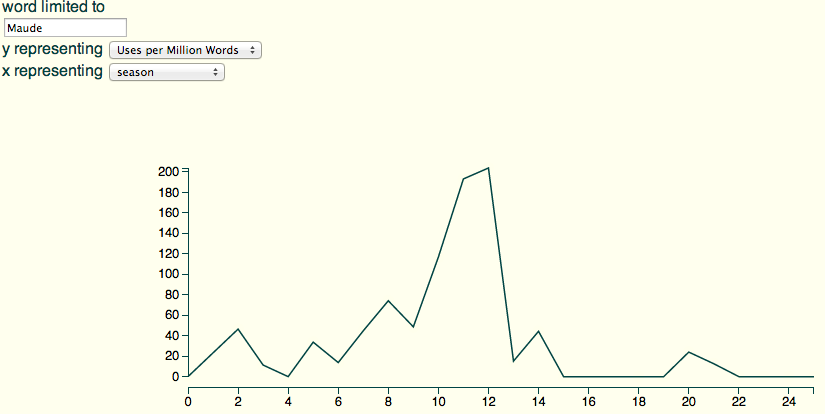
Just trying some line charts: yep, Maude only gets mentioned much by name around the season she dies:
But what’s really interesting, maybe, isn’t the season-to-season change but the internal episode structure. For instance, at what minute in the episodes do characters talk about “school?”
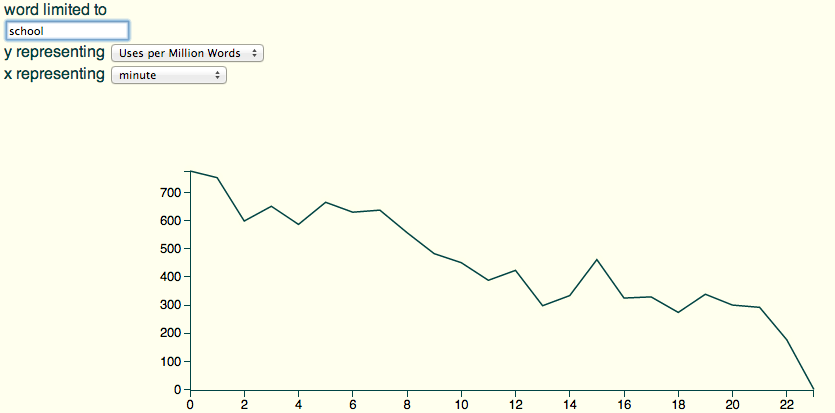
That’s pretty interesting, actually: pretty much every minute, the plots seem to shift away from school.
Likewise, “I’m Kent Brockman” seems to be overwhelmingly a gag from the opening scene:

OK, that’s enough: here’s the link to the Bookworm, and here’s the source code.