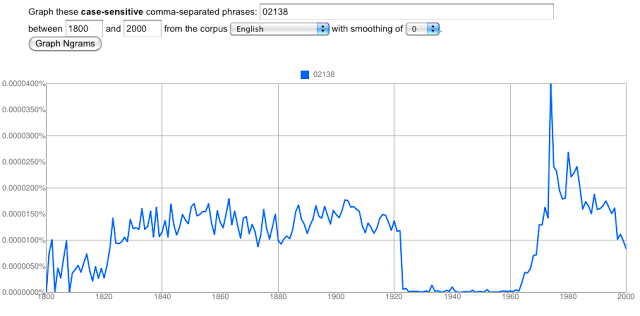
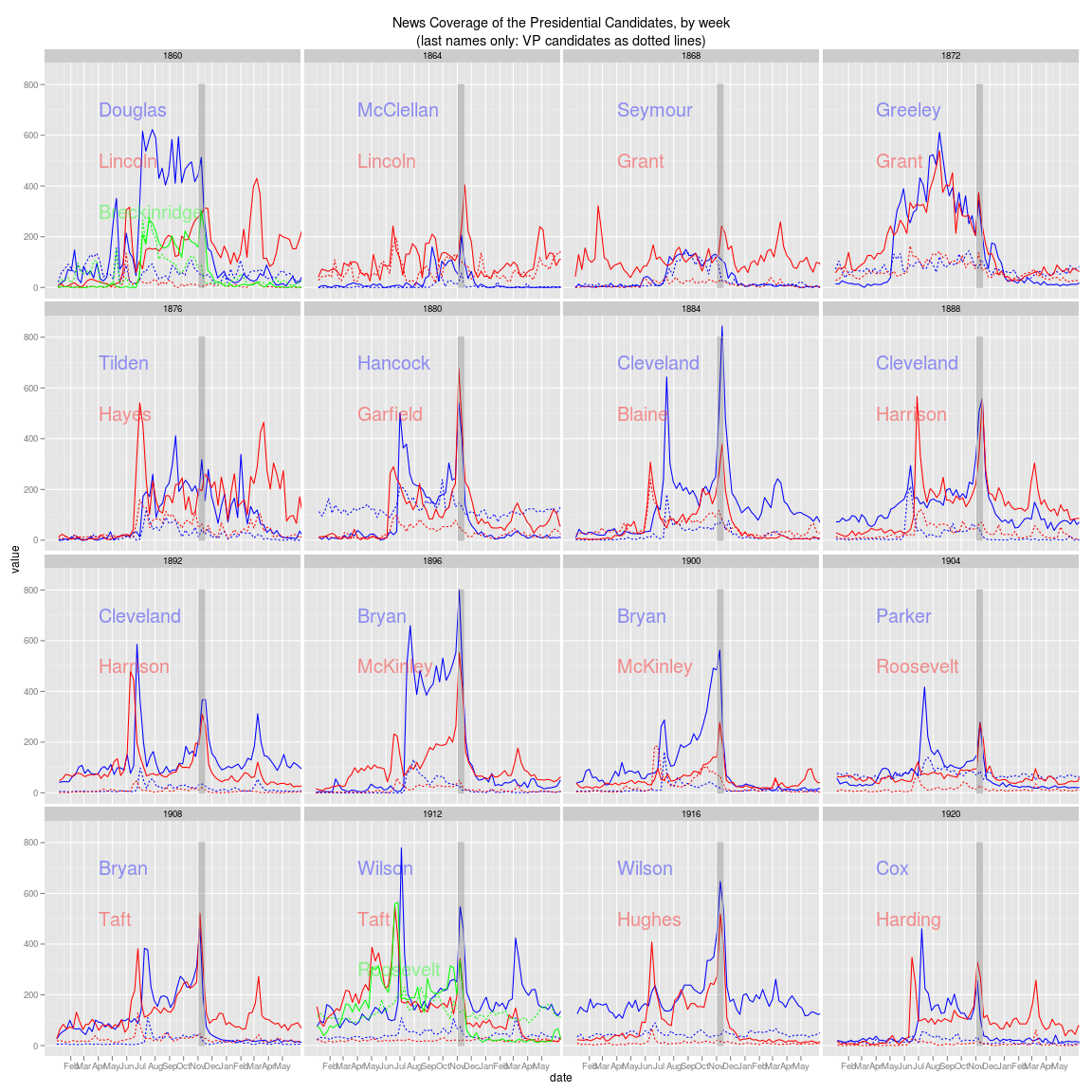
queryA = list("database"="RMP","search_limits" = list("gender"=list("female"),"rHelpful" = list("$lte" = list(2)),"department"=list("Computer Science"),"date_year" = list("$gte"=list(2005))),counttype=list("WordCount"),groups=list("unigram"))
queryB = queryA
queryB[['search_limits']][['gender']] = list("male")
goodwords = compareTwoLanguages(queryA,queryB)
historyPositive=goodwords %.% filter(!unigram %in% genderStopwords) %.% filter(-abs(dunning)0,"Female","Male"))
ggplot(historyPositive) + geom_bar(aes(y=dunning,x=reorder(unigram,abs(dunning)),fill=genderBias),stat="identity") + coord_flip() + labs(x="Word",y="Overrepresentation (Dunning Log score)") + theme(axis.text=theme_text(size=12)) + labs(title="Gender-specific words in negative CS reviews")