Terms
- Word Embedding: A general strategy for treating words as numbers.
- Word2Vec: An algorithm that performs a particularly useful word embedding.
- wordVectors: an actual program you can run inside Rstudio to do this yourself.
Word Embeddings
What kind of space?
Two dimensions is not enough!
Neither is 3!
http://benschmidt.org/3dtsne
Word2Vec uses a few hundred dimensions
France 0.01500453 0.018186183 0.08340119 0.009556154 0.016695607 0.007973551 ...
Germany 0.06001414 0.046422540 0.06336951 0.002588225 -0.063688305 -0.026276992
wine -0.04239146 -0.031893139 -0.05403588 0.033243816 0.002391649 0.048410353Similarities
Reading vectors in:
library(wordVectors)
news = read.vectors("~/word2vec_models/short_google_news.bin")Creating Models
Which algorithm to use?
Major options are:
*word2vec: Fast, general-purpose, laptop-friendly.
GloVe: Better theoretical grounding, better if you're running many models on a server. Scales poorly.
swivel: _(ツ)_/¯
Best advice:
Word2vec with skip-gram negative sampling
Word2Vec on small (less than 1 million words) corpora
Think again
Try greatly expanding the window--default is 12 but try 50,
Run many iterations. A hundred, maybe. If your model trains in less than a minute, it's probably no good.
Some notes on preparation:
- You must have a single text file.
- For anything less than a massive corpus, lowercasing is a good idea.
- Bundling bigrams together can be helpful.
- the
prep_word2vecfunction in my package handles all this, slowly.
Relationships
Semantic vectors have meaning
"Capitalness" (?)

Creating a relational vector
male_female = model[["man"]] - model[["woman"]]teaching_vectors %>% nearest_to(teaching_vectors[["hola"]])
## hola espanol todos fantastico porque
## -4.440892e-16 5.419217e-01 5.561170e-01 5.582298e-01 5.584173e-01
## interesante buen simpatico muy profesora
## 5.646364e-01 5.702220e-01 5.703893e-01 5.707483e-01 5.709447e-01teaching_vectors %>% nearest_to(teaching_vectors[["hola"]]-teaching_vectors[["spanish"]])
## hola hi goodmorning mmmmmkay wassup hello
## 0.2541650 0.6992011 0.7123197 0.7195401 0.7225225 0.7289345
## todos uhm hahahahah quot
## 0.7447951 0.7485577 0.7516170 0.7620057teaching_vectors %>% nearest_to(teaching_vectors[["hola"]] - teaching_vectors[["spanish"]] + teaching_vectors[["french"]],n=5)
hola bonjour french revoir madame
0.1282269 0.5520502 0.6021849 0.6156018 0.6170013
Frontiers: rejection
"Semantics derived automatically from language corpora necessarily contain human biases," Caliskan-Islam et al.
Translations to English from many gender-neutral languages such as Finnish, Estonian, Hungarian, Persian, and Turkish lead to gender-stereotyped sentences. For example, Google Translate converts these Turkish sentences with genderless pronouns: “O bir doktor. O bir hems ̧ire.” to these English sentences: “He is a doctor. She is a nurse.”
"Semantics derived automatically from language corpora necessarily contain human biases," Caliskan-Islam et al.
We demonstrate here for the first time what some have long suspected (Quine, 1960)—that semantics, the meaning of words, necessarily reflects regularities latent in our culture, some of which we now know to be prejudiced.
"Semantics derived automatically from language corpora necessarily contain human biases," Caliskan-Islam et al.
First, our results suggest that word embeddings don’t merely pick up specific, enumerable biases such as gender stereotypes (Bolukbasi et al., 2016), but rather the entire spectrum of human biases reflected in language. [...] Bias is identical to meaning, and it is impossible to employ language meaningfully without incorporating human bias.
Alternative: (Schmidt 2015, Bolukbasi et al., 2016):
What's new here is not that bias is finally proven, but that we manipulate around it.
genderless = news %>%
reject(news[["he"]] - news[["she"]]) %>%
reject(news[["man"]] - news[["woman"]]) %>%
Debiased pairs from rateMyProfessors
# [1] "he->she" "hes->shes"
# [3] "himself->herself" "his->her"
# [5] "man->woman" "guy->lady"
# [7] "grandpa->grandma" "dude->chick"
# [9] "wife->husband" "grandfather->grandmother"
# [11] "dad->mom" "uncle->aunt"
# [13] "fatherly->motherly" "brother->sister"
# [15] "actor->actress" "grandfatherly->grandmotherly"
# [17] "father->mother" "genius->goddess"
# [19] "arrogant->snobby" "priest->nun"
# [21] "dork->ditz" "handsome->gorgeous"
# [23] "atheist->feminist" "himmmm->herrrr"
# [25] "kermit->degeneres" "mans->womans"
# [27] "hez->shez" "himmm->herrr"
# [29] "trumpet->flute" "checkride->clinicals"
# [31] "gay->lesbian" "surgeon->nurse"
# [33] "daddy->mommy" "cool->sweet"
# [35] "monsieur->mme" "jolly->cheerful"
# [37] "jazz->dance" "wears->outfits"
# [39] "girlfriends->boyfriends" "drle->gentille"
# [41] "gentleman->gem" "charisma->spunk"
# [43] "egotistical->hypocritical" "cutie->babe"
# [45] "wingers->feminists" "professore->molto"
# [47] "gruff->stern" "demonstrations->activities"
# [49] "goofy->wacky" "coolest->sweetest"
# [51] "architect->interior" "sidetracked->frazzled"
# [53] "likeable->pleasant" "grumpy->crabby"
# [55] "charismatic->energetic" "cisco->cna"
# [57] "masculinity->gender" "girlfriend->boyfriend" Frontiers: alignment
Aligning multiple models.
Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change
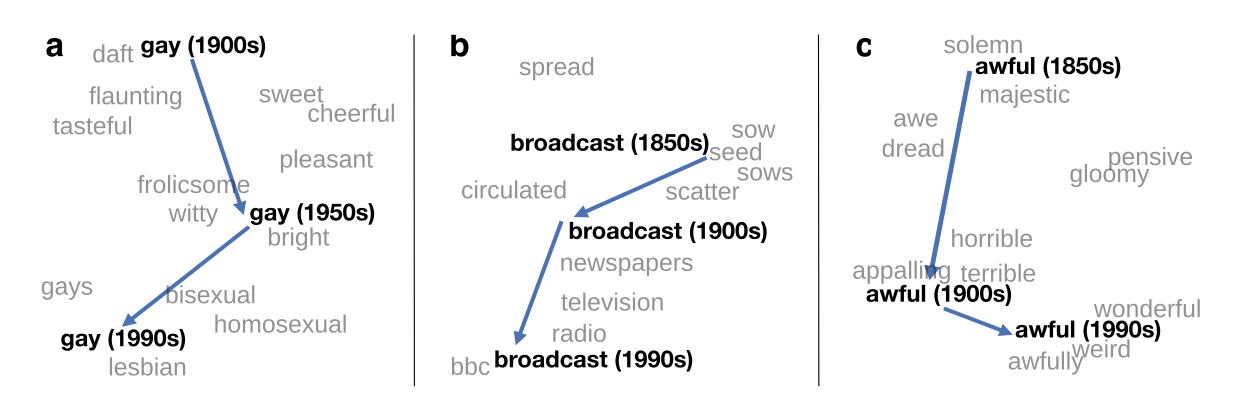
Hansard Corpus