Word Embeddings for the Humanities and Social Sciences
Ben Schmidt
2018-06-01
Getting started
Downloads
- Worksheet with code to edit: in the folder.
Choose 2 or 3 sources.
- “r/books,” 2016
- “r/The_Donald,” 2016
- “r/politics,” 2016
- GloVe. A widely-used set of embeddings which contains millions of words in the full version.
- RMP: All the reviews of faculty members from RateMyProfessors.com
- Hansard: Several different sets of debate transcriptions from the British parliament, identified by year.
- Streets: What if each census tract in the US were a text composed of the street names in it?
Rstudio and R Markdown
Task now: Using the sources at benschmidt.org/pittsburgh successfully run the first block of code. (Not this one)

What are word embeddings?
Terms
- Word Embedding: A general strategy for treating words as numbers.
- Word2Vec: An algorithm that performs a particularly useful word embedding.
- wordVectors: an actual program you can run inside Rstudio to do this yourself. (If you like python, use gensim).
Word embeddings place words into space that does the following:
- Approximate semantic distance as spatial distance for computation.
- Approximate frequent relationships as vectors in space.
Predicting words from context.

Source: Conor McDonald
Two dimensions is not enough! Neither is 3! 3d embeddings (a bad idea)!
Word2Vec uses a few hundred dimensions for each word. Here are some.
| country | V1 | V2 | V3 | V4 | V5 | V6 |
|---|---|---|---|---|---|---|
| France Germany wine | 0.01500453 0.06001414 -0.04239146 | 0.018186183 0.046422540 -0.031893139 | 0.08340119 0.06336951 -0.05403588 | 0.009556154 0.002588225 0.033243816 | 0.016695607 -0.063688305 0.002391649 | 0.007973551 -0.026276992 0.048410353 |
Word Embeddings and Topic Models
- Word embeddings try to create a detailed picture of language in a corpus: topic models try to simplify the vocabulary in each text into a higher level abstraction than an individual word.
Topic Models are better than word embeddings because:
- They represent documents as important elements and let you make comparisons across them.
- They can handle words with multiple meanings sensibly.
- They let you abstract away from words to understand documents using broad measures.
Word embeddings are better than topic models because
- They retain words as core elements and let you make comparisons among them or generalize out from a few to many others.
- They make it possible (not easy) to define your own clusters of interest in terms of words.
- They let you abstract away from documents to understand words.
The embedding strategy (“Representation Learning”)
- Ascendant in Machine Learning today
- Define a generally useful task, like
- predict a word from context
- identify the content of an image
- predict the classification of a text
- Find a transformation function that creates a representation of about 100 to 5000 numbers that works well at that task.
- The same function may be generally useful in other contexts.


WEMs: Word similarities
Loading vectors
Creating Models
What Algorithm should I use?
Major options are:
word2vec: Fast, general-purpose, laptop-friendly.
GloVe: Better theoretical grounding, better if you’re running many models of different dimensionality on a server. Scales poorly.
But at this point, you could go crazy
Swivel, Poincaré (hierarchical) embeddings, Bernoulli Embeddings, and more.\_(ツ)_/¯
What Algorithm should I use?
Short Answer: word2vec with skip-gram negative sampling.
Probably using my R package or gensim for python
Word2Vec on small (less than 1 million words) corpora
Think again
Try greatly expanding the window–default is 12 but try 50,
- Run many iterations. A hundred, maybe. If your model trains in less than a minute, it’s probably no good.
Some notes on preparation:
- You must have a single text file.
- For anything less than a massive corpus, lowercasing is a good idea.
- Bundling bigrams together can be helpful.
- the
prep_word2vecfunction in my package handles all this, somewhat slowly.
Relationships
Semantic vectors have meaning
“Capitalness” (?)

Creating a relational vector
OR
teaching_vectors %>% closest_to(teaching_vectors[["hola"]] -
teaching_vectors[["spanish"]] + teaching_vectors[["french"]],n=5)| hola | bonjour | fr | ench r | evoir madame |
|---|---|---|---|---|
| 0.12 | 82269 0.5 | 520502 | 0.60218 | 49 0.6156018 0.6170013 |

Frontiers: rejection and de-biasing
“Semantics derived automatically from language corpora necessarily contain human biases,” Caliskan-Islam et al.
Translations to English from many gender-neutral languages such as Finnish, Estonian, Hungarian, Persian, and Turkish lead to gender-stereotyped sentences. For example, Google Translate converts these Turkish sentences with genderless pronouns: “O bir doktor. O bir hems ̧ire.” to these English sentences: “He is a doctor. She is a nurse.”
“Semantics derived automatically from language corpora necessarily contain human biases,” Caliskan-Islam et al.
We demonstrate here for the first time what some have long suspected (Quine, 1960)—that semantics, the meaning of words, necessarily reflects regularities latent in our culture, some of which we now know to be prejudiced.
Alternative: (Schmidt 2015, Bolukbasi et al., 2016):
What’s new here is not that bias is finally proven, but that we manipulate around it.

Debiased pairs from rateMyProfessors
# [1] "he->she" "hes->shes"
# [3] "himself->herself" "his->her"
# [5] "man->woman" "guy->lady"
# [7] "grandpa->grandma" "dude->chick"
# [9] "wife->husband" "grandfather->grandmother"
# [11] "dad->mom" "uncle->aunt"
# [13] "fatherly->motherly" "brother->sister"
# [15] "actor->actress" "grandfatherly->grandmotherly"
# [17] "father->mother" "genius->goddess"
# [19] "arrogant->snobby" "priest->nun"
# [21] "dork->ditz" "handsome->gorgeous"
# [23] "atheist->feminist" "himmmm->herrrr"
# [25] "kermit->degeneres" "mans->womans"
# [27] "hez->shez" "himmm->herrr"
# [29] "trumpet->flute" "checkride->clinicals"
# [31] "gay->lesbian" "surgeon->nurse"
# [33] "daddy->mommy" "cool->sweet"
# [35] "monsieur->mme" "jolly->cheerful"
# [37] "jazz->dance" "wears->outfits"
# [39] "girlfriends->boyfriends" "drle->gentille"
# [41] "gentleman->gem" "charisma->spunk"
# [43] "egotistical->hypocritical" "cutie->babe"
# [45] "wingers->feminists" "professore->molto"
# [47] "gruff->stern" "demonstrations->activities"
# [49] "goofy->wacky" "coolest->sweetest"
# [51] "architect->interior" "sidetracked->frazzled"
# [53] "likeable->pleasant" "grumpy->crabby"
# [55] "charismatic->energetic" "cisco->cna"
# [57] "masculinity->gender" "girlfriend->boyfriend" Frontiers: alignment
Aligning multiple models.
Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change
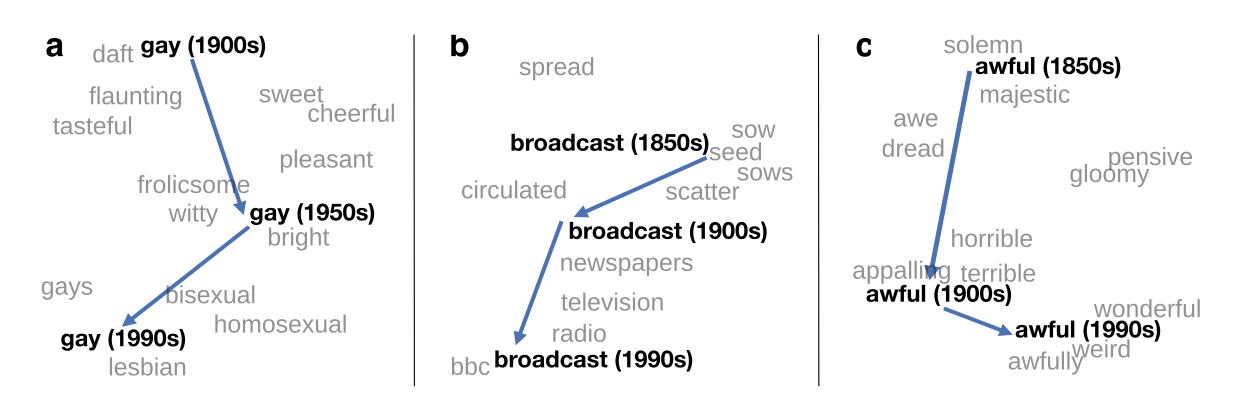
Hansard Corpus