Acknowledgements
Institutions
Northeastern University/Rice University Cultural Observatory
Erez Lieberman Aiden
Neva Cherniavsky, Martin Camacho, Matt Nicklay, Billy Janitsch, JB Michel.
Funders
- Digital Public Library of America
- Harvard Cultural Observatory
- National Endowment for the Humanities

- github.com/Bookworm-project
- bookworm.culturomics.org
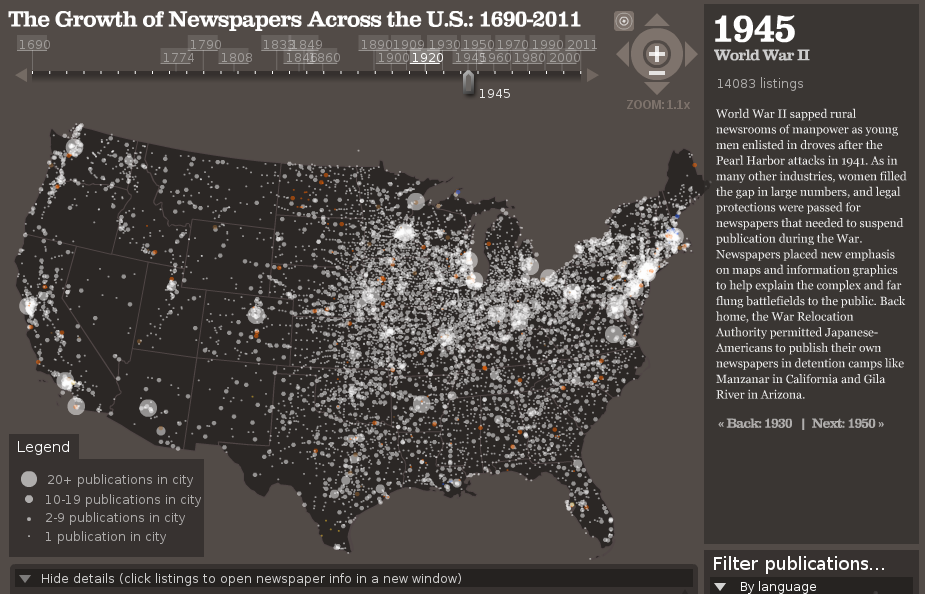
Bill Lane Center for the American West: http://www.stanford.edu/group/ruralwest/cgi-bin/drupal/visualizations/us_newspapers
Textual Metadata: Correspondence Networks
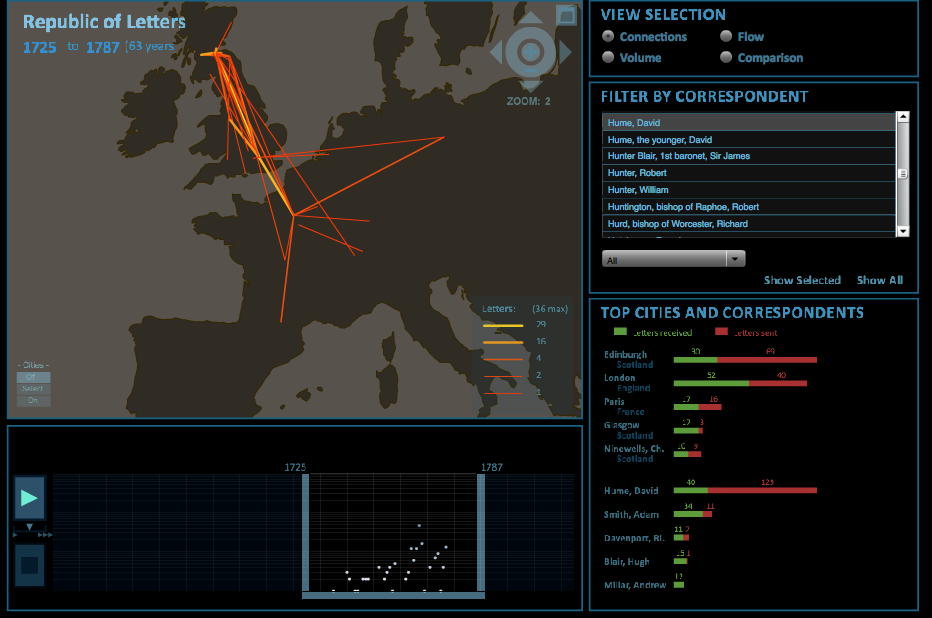
Mapping the Republic of Letters
Textual Metadata: Trial Lengths
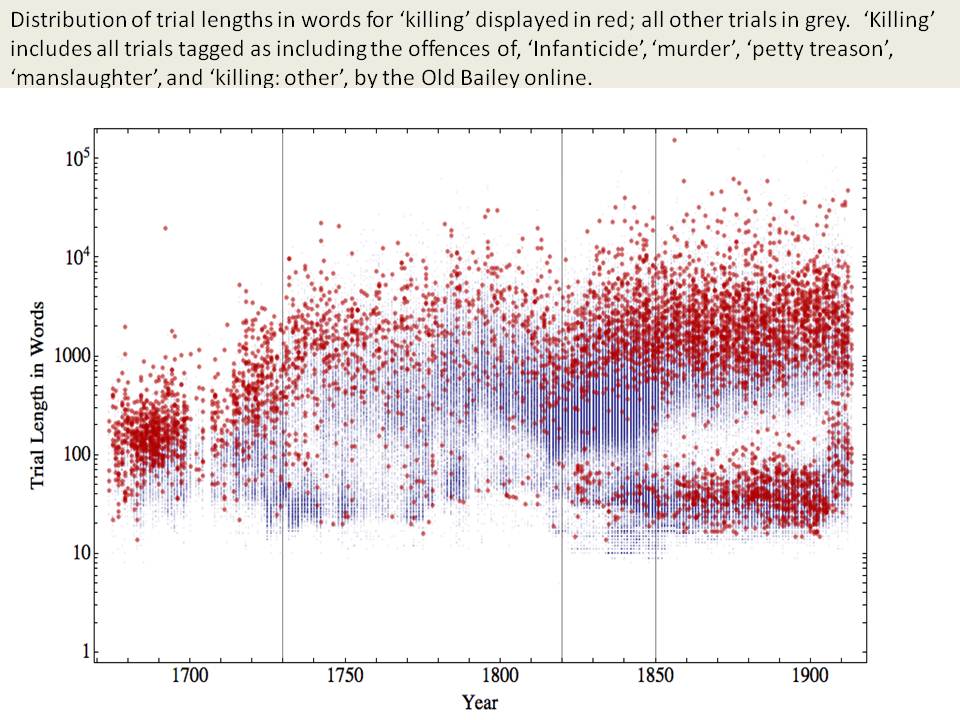
Data Mining with Criminal Intent/The Old Bailey Online
ICOADS Deck 701, US Maury Collection (1789-c.1865) ICOADS
ICOADS Deck 735, Russian Research Vessel (R/V) Digitization
02138
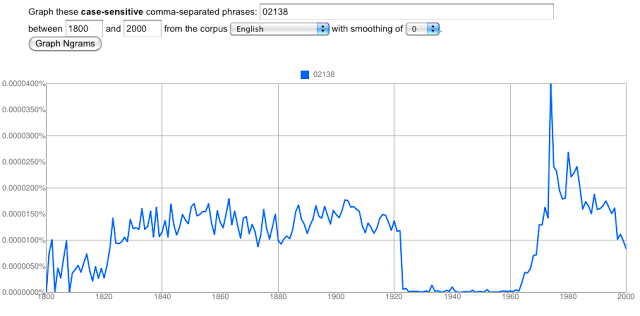
02138
Google Partner Libraries
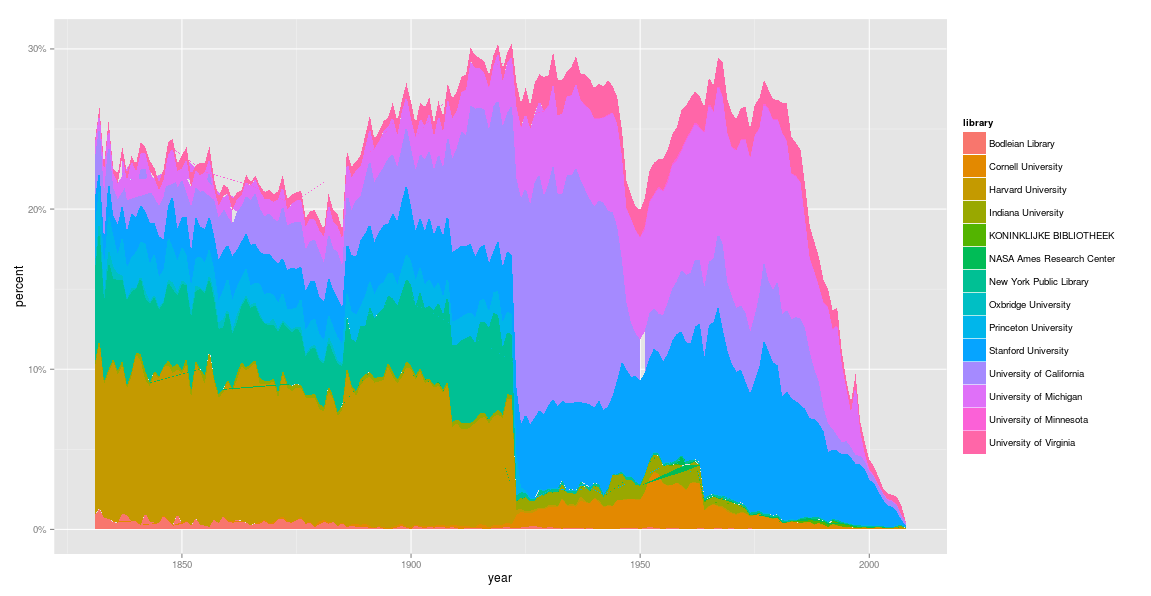
Bookworm Open Library

- 1 million books, 91 billion words
Some public Bookworm instances:
- Science articles: bookworm.culturomics.org/arxiv
- Movies and television: movies.benschmidt.org
Vogueworm (Yale University): full run of Vogue Magazine
http://bookworm.library.yale.edu/collections/vogue/ 
Medical Heritage Library (30,000 medical books)

Hathi Trust
http://sandbox.htrc.illinois.edu/bookworm/
II. A grammar of text analysis
Bookworm Core Philosophy--infrastructures
- Text curators can enable new uses by sharing.
- Large text collections share fundamental problems of
- Data visualization is a primary output.
- Responses should be under a second.
- Historical Newspapers: bookworm.culturomics.org/ChronAm
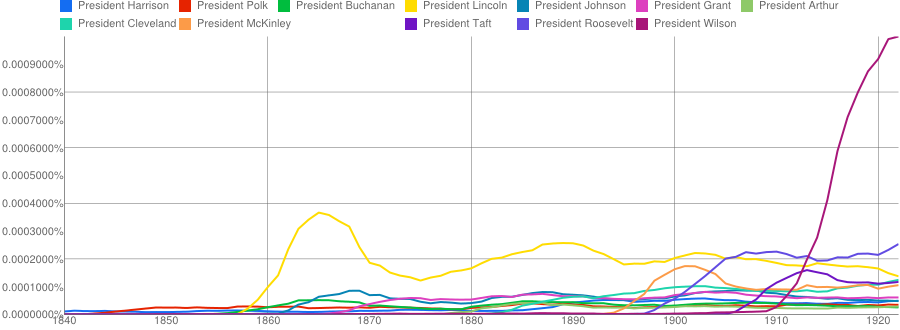
Mentions of US Presidents in Ngrams and the Chronicling America Bookworm
The 1896 Eelection: Candidates by news coverage
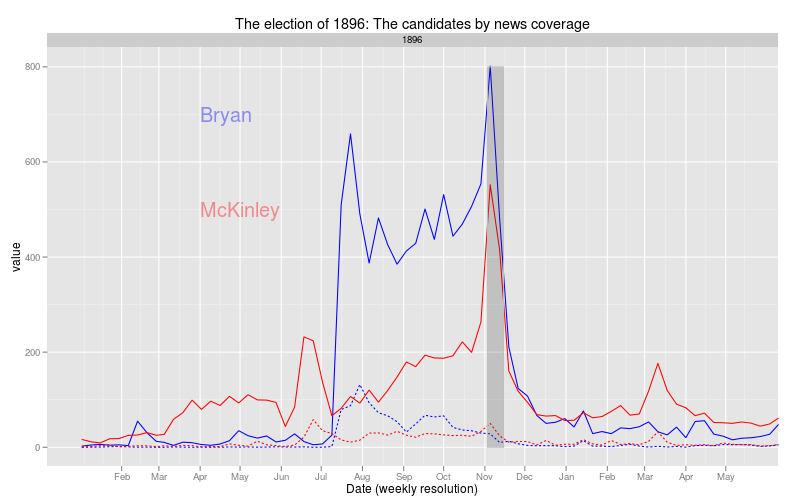
Coverage of presidential candidates in the 1896 election by candidate last name
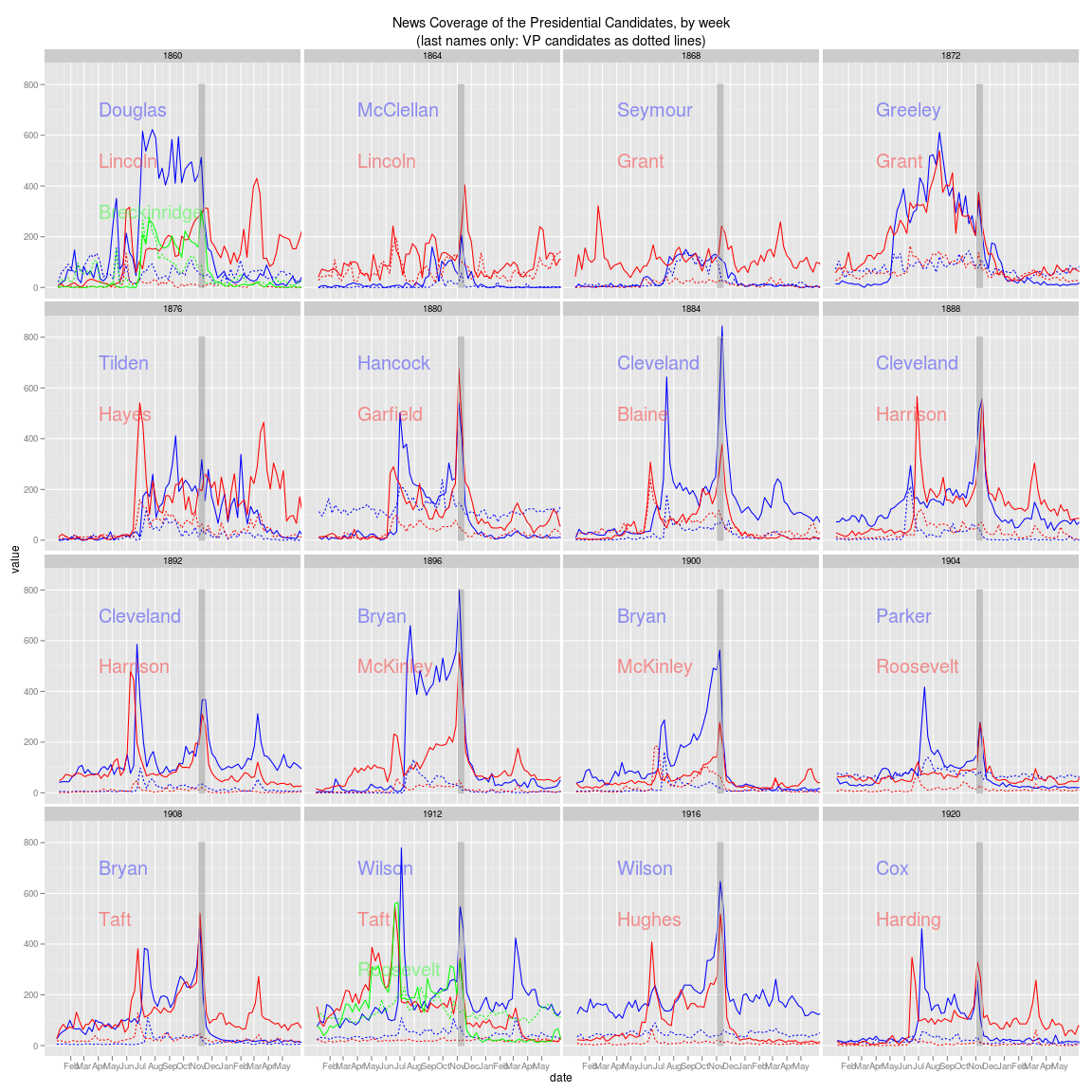
Coverage of all presidential elections, 1860-1920

Defining Text groups and tokenizations.
Statistics returnable from comparing text and token counts across two collections:
- Percentage of Texts
- Uses per million words
- Average length of books.
- TF-IDF
- Dunning Log-likelihood.
- ???
How Humanists use topic models badly:
- Only perfunctory efforts to link back into other forms of metadata.
- Straightforward use as dimensionality-reduction without spot checks.
- Assumption of stability in a single topic's composition across time, genre, etc.
Demo 1
{"database": "ChronAm",
"plotType": "map",
"method": "return_json",
"search_limits": {},
"aesthetic": {
"point": "placeOfPublication_geo",
"size": "TextCount"
}}
Demo 2
{"database": "ChronAm",
"plotType": "map",
"method": "return_json",
"search_limits": {},
"aesthetic": {
"point": "placeOfPublication_geo",
"size": "TextCount",
"time": "publish_year"}}
Newspaper flu coverage, 1917-1919
{"database": "ChronAm",
"plotType": "map",
"method": "return_json",
"search_limits": {"word":["flu","influenza"],
"publish_year":{"$lte":1920,"$gte":1917}},
"smoothingSpan":25,
"aesthetic": {
"time":"publish_day",
"point": "placeOfPublication_geo",
"size": "TextPercent"}}
A Viral Text
{"database": "viral",
"plotType": "map",
"method": "return_json",
"search_limits": {
"chunk": [6]
},
"aesthetic": {
"point": "placeOfPublication_geo",
"size": "WordCount",
"time": "date_year"}}
Viral Texts: Ryan Cordell and David Smith, Northeastern University
Viral Topics
{"database": "viral",
"plotType": "map",
"method": "return_json",
"search_limits": {
"topic": {
"$gte": 10
}
},
"aesthetic": {
"point": "placeOfPublication_geo",
"size": "WordCount",
"time": "topic",
"label": "topic_label"}}
What does this tell us that we haven't seen already?